
Bien concevoir ses composants, les bases d’un design system évolutif
Comment concevoir des systèmes de composants flexibles réutilisables et modulaires ? Des composants qui s’adaptent à la taille du navigateur ou leur contexte d’affichages ? Des composants qui s’adaptent au vrai contenu “non idéal”s ? Des composants qui s’adaptent aux différents cas d’usage des utilisatrices et utilisateurs ? Je vous propose aujourd’hui un gros aperçu de mon processus de conception pour désigner des systèmes modulaires qui s’adaptent à la réalité d’un produit, aussi complexe soit elle. Cet article est tiré d’une conférence du même nom dont vous trouverez la vidéo à la fin.
Sommaire
L’article en long, vous pouvez naviguer plus rapidement dans les sections ici :
- Design de composants réutilisables
- Variations et adaptations à différentes densités de contenus
- Variations et adaptations liées à l’interactivité et au contexte d’usage
- En résumé, le TL;DNR
- La vidéo de la conférence
J’en profite pour vous rappeler que le contenu de cet article, les images et le design des slides ne sont pas libres de droits. Vous n’avez normalement pas le droit de les réutiliser sans mon autorisation. Donc soyez sympa, si vous voulez utilisez ce contenu, demandez-moi avant et citez cet article comme source. Merci.
Design de composants réutilisables
Pour désigner un système évolutif, on veut tout d’abord créer des composants réutilisables. Pour cela, tout commence pour moi par l’architecture d’information… Au fil du temps, de mes lectures et travaux, j’ai affiné la façon dont je travaille qui est un mélange de différentes lectures et workshops, incluant :
- Un workshop de stratégie mobile et responsive en 2015 donné par Karen McGrane auquel j’ai eu la chance d’assister et son livre Content Strategy for Mobile
- Le livre How to make sense of any mess de Abby Covert
- Le livre Content Everywhere, Strategy and Structure for Future-Ready Content de Sara Wachter-Boettcher
- Le livre Everyday Information Architecture de Lisa Maria Marquis
- L’article Content Modelling par Rachel Lovinger
- L’article de OOUX par Sophia V. Prater pour la partie méta-données. Je trouve la nouvelle version renommée ORCA trop compliquée pour mes besoins au final
0. Faire sa recherche utilisateur
L’étape zéro de tout bon design pour moi est de faire sa recherche utilisateur en amont (oui, je sais, parfois ce n’est pas toujours facile).
Quand la recherche utilisateur est bien faite, elle permet d’extraire des besoins et des patterns du côté des utilisatrices et utilisateurs. La recherche va donc permettre de guider ce qui sera dans vos pages et vos composants. Cela permettra également de vous aider à faire des arbitrages en termes d’importance sur la page ou dans le parcours de tel ou tel contenu (on y revient dans l’étape 2. sur la priorisation).
Comment faire sa recherche est en dehors du périmètre de cet article, mais voilà quelques pistes de questions à vous poser pour vous guider :
- Quelle(s) tâche(s) et activité(s) la personne qui utilise mon interface essaie d’accomplir ?
- De quoi a-t-elle besoin pour accomplir ces tâches ?
- Qu’est-ce qui, quels contenus ou types de contenus pourraient la freiner ?
- Qu’est-ce qui, quels contenus ou types de contenus pourraient l’aider ?
- Quand estime-t-on que la tâche soit accomplie ? Quand est-ce un échec ?
- Etc.
C’est là où une collaboration entre les équipes de design plutôt côté UI et les équipes de recherche est très importante.
1. Travailler l’architecture d’information et le un modèle de contenu
Je suis une grande fan du livre de Abby Covert “How to make sense of any mess”. En général, face à un problème compliqué, je commence par le découper en petits morceaux et tout mettre à plat. Dans mon métier on appelle ça « travailler l’architecture d’information ». Et pour des composants, ces petits morceaux sont souvent les différents types de contenus et de contenus dont je vais avoir besoin. Avant de designer le moindre composant, je commence donc par modéliser les types de contenus dont je vais avoir besoin dans l’interface au niveau des pages et de mes composants.
Au début, je faisais ça sous forme d’une longue colonne de Post-it sur un mur, méthode inspirée de l’atelier que Karen McGrane. Comme je suis passée en remote à plein temps depuis un an et demi, en ce moment c’est sur miro. Mais le fond reste le même :
- Je liste les types de contenus principaux et / ou type de pages dont je vais avoir besoin sur ce site / interface. Ce qui va m’aider ici, c’est la recherche utilisateur. Et sur un site existant, toutes les méthodes d’analyse de contenu (voir le livre “Everyday Information Architecture” de Lisa Maria Marquis) . Par exemple, sur un site de recette de cuisine, je vais avoir des recettes, sans doute des auteurs, des ingrédients, etc. Pour un site qui classe des films je vais avoir des films, des auteures, des réalisatrices, etc.
- Je liste ensuite de quoi est composé ce contenu. En général, les différents articles et livres qui parlent d’architecture d’information et de contenus ont tendance à appeler ça des attributs. Une recette de cuisine a par exemple un titre, une photo, des étapes, un sommaire, des ingrédients, une note, un nombre d’avis, etc.
Petite note : le modèle de contenu m’aide à designer mes pages et composants. Mais il aide aussi en général les équipes de développement à designer le back-end, les APIs et la structure de la base de données. N’hésitez donc pas à le partager.
Sur des composants plus compliqués, je vais parfois aussi lister les interactions. Ces interactions vont parfois créer des variantes des composants (mode lecture seule, édition, etc.).
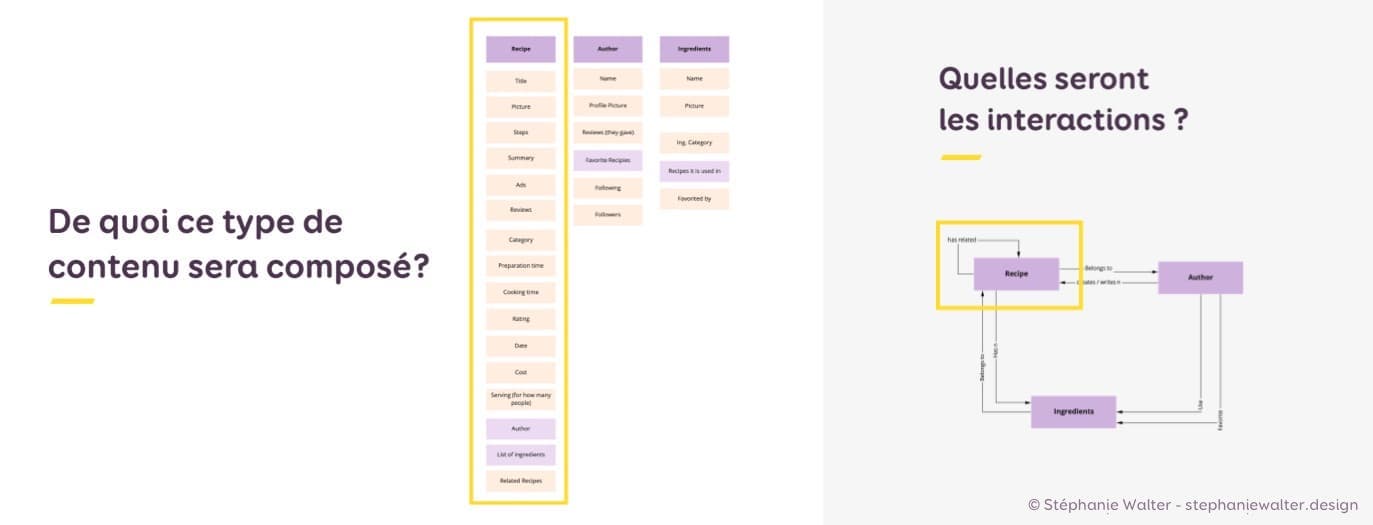
Quand le modèle est long, je tague parfois certains attributs comme étant des métadonnées. Ce sont des attributs particuliers dont on se sert souvent pour classer, faire des listes, des recherches, des filtres, etc. Sur un site de recette de cuisine, on pense aux catégories, au coût, au temps de préparation, etc.
2. Tris de cartes pour classer et prioriser
Une fois que j’ai ma liste d’ingrédients (haha) de ce dont est composé ce type de contenu, en général je m’intéresse à la priorité des éléments qui le composent.
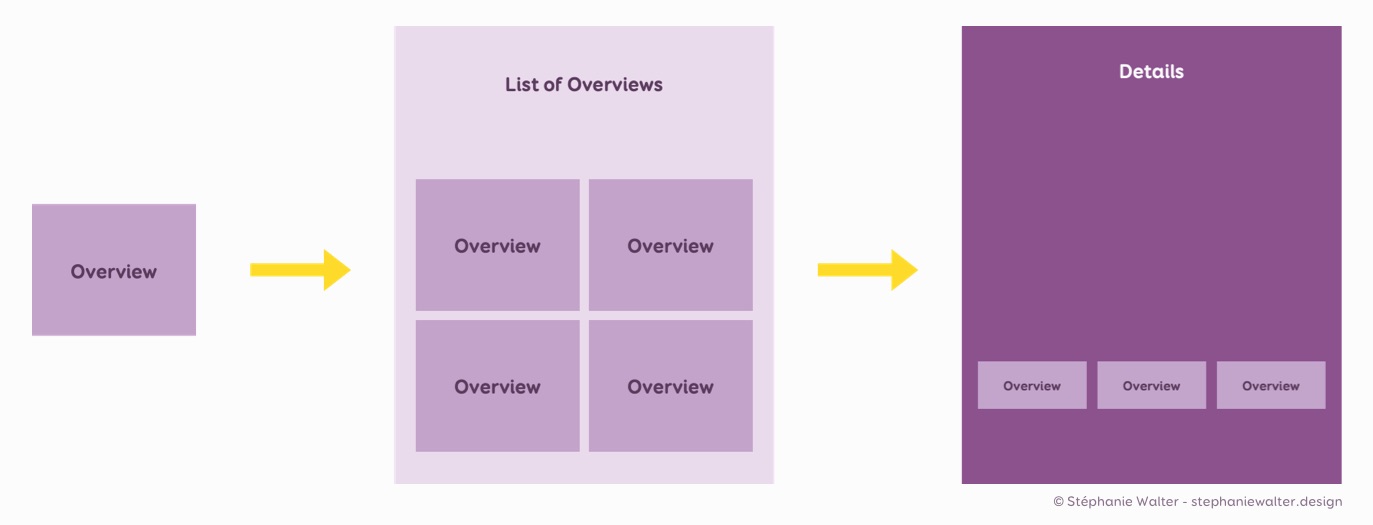
Un modèle Résumé > Détail
Quand on creuse un peu, on se rend compte qu’une grosse partie de nos sites fonctionne sur un modèle résumé > détail. Et qu’une grande partie des pages sont soit des listes de résumés, soit des pages de détails. Quelques exemples :
- Un blog: une liste de résumé d’articles qui mènent à un article (détail)
- Un site e-commerce: une liste de résumés de produits qui mènent à une fiche produit (on pourrait argumenter que le panier est également une liste de résumés)
- Une application d’e-mail: une liste de résumés qui mènent au mail complet détaillé
Ai-je besoin de continuer ?
En général je priorise les éléments à l’intérieur de mon type de contenu du plus important en haut au moins important en bas. C’est là où le faire sur un mur était pratique
À partir de là j’ai une bonne base pour :
- Extraire des minis composants de type “résumé” en utilisant surtout ce qui se trouve en haut de ma liste puisque c’est ce qui permettra à la personne de déterminer si elle veut cliquer ou non sur la miniature / carte
- Créer la structure d’une page détaillée, encore une fois avec les contenus les plus importants en haut de page.
- Quand on a beaucoup d’attributs, on finit parfois à partir de cette liste par créer plusieurs pages détaillées sur plusieurs niveaux. Du coup on peut même créer des “sous” types de contenus parfois sur des projets très complexes en termes de données.
- Prioriser sur du responsive puisque souvent sur mobile on a une seule colonne avec encore une fois les contenus les plus importants vers le haut.
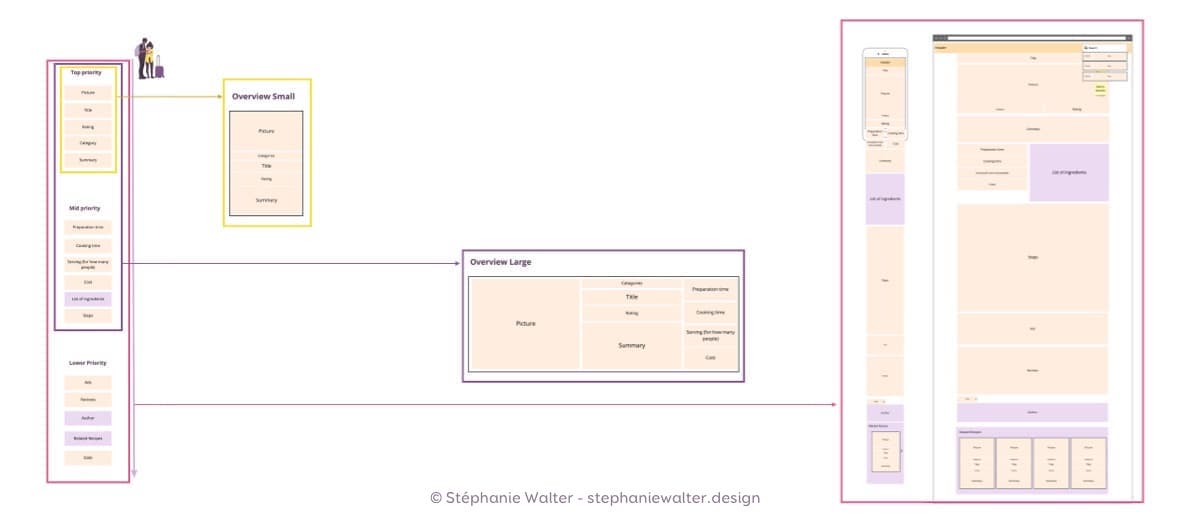
D’une colonne de contenu classé par priorité on peut créer des petits composants de « résumé », des plus gros, voir une page entière
Utilisez votre recherche utilisateur !
À ce stade vous devez sans doute vous demander “mais comment on décide ce qui est important ou pas?”. On ne décide pas arbitrairement. On le fait en fonction des données collectées lors de la recherche utilisateur faite en amont (souvenez-vous, étape 0).
Et s’il y a des éléments pour lesquels l’équipe ne s’accorde pas sur la priorité, c’est souvent là qu’on ira creuser avec plus de recherche. Cela permet de mieux comprendre ce qui va impacter les décisions des utilisatrices et utilisateurs et leurs besoins.
Exemple sur un vrai projet
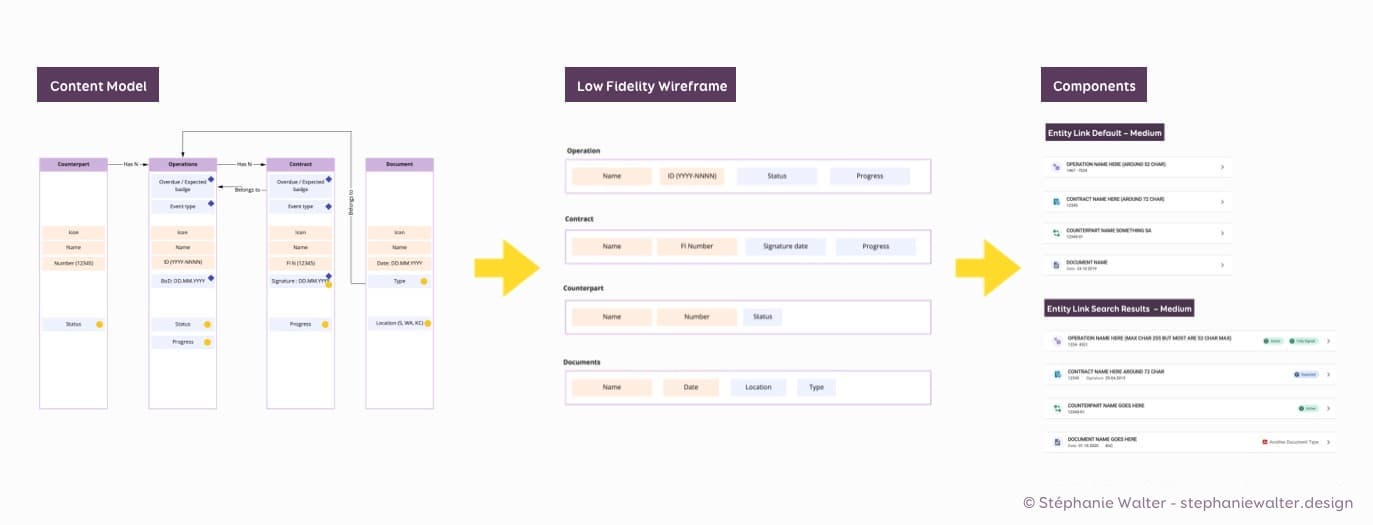
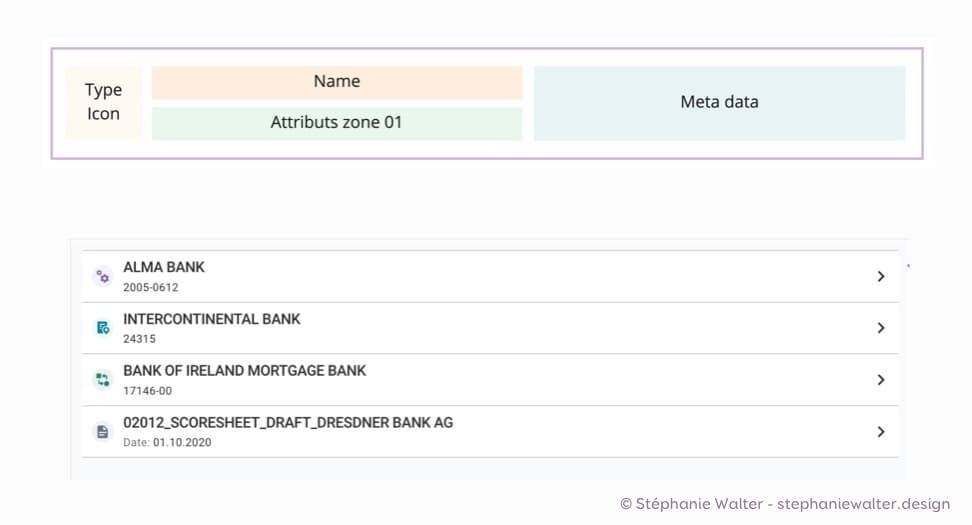
Si je prends un exemple concret sur un projet un poil plus complexe que des sites de recette de cuisine… J’ai un site avec des opérations financières. Nous avons la page détaillée d’une opération. Mais nous avons aussi besoin de composants de “navigation” qu’on appelle “entity link item” qui permettra de lister les opérations à différents endroits de l’interface. Le modèle de contenu de l’opération est très compliqué, car il va contenir beaucoup d’éléments. Tellement compliqué qu’au final, on va structurer et répartir ces attributs de contenus en “sous types” sur plusieurs pages de détails.
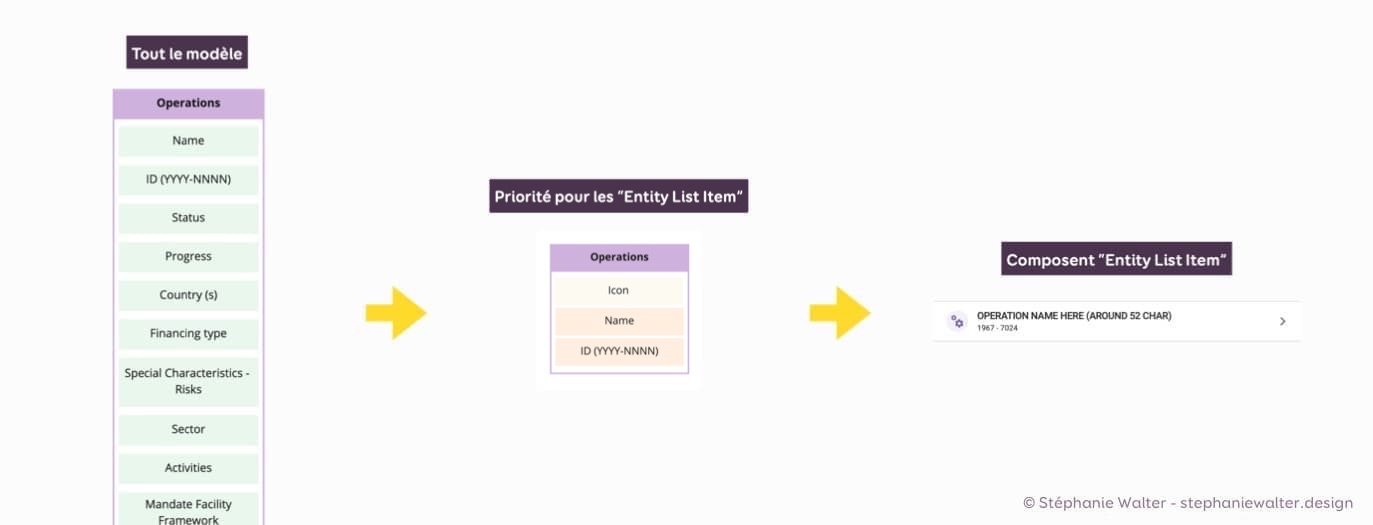
Du modèle de contenu complet, au modèle du composant, au composant.
À partir de ma priorisation de contenus, je peux “garder” la partie du modèle de contenu qui va aider l’utilisatrice à décider de cliquer ou non sur cet élément (ici c’est la partie qui identifie l’opération) pour créer ce composant de liste / navigation qu’on appelle chez nous “entity list item”.
3. Identifier les variations et composants similaires
En général, on essaie de réutiliser un maximum nos composants quand c’est possible. Identifier où et comment pour factoriser les utilisations peut permettre de faire gagner par mal de temps aux équipes
À partir de là je me pose souvent la question de “Existe-t-il des variations qui pourraient utiliser le même composant ?”. On peut imaginer différents types de variations
- Le même composant en édition vs lecture seule.
- Le même composant dont certains attributs changent en fonction du type d’utilisatrice et de ses droits.
- Le même composant qui change en fonction de là où se trouve la personne dans le parcours (j’y reviens dans la dernière partie)
- Le même composant avec différents états (j’y reviens dans la dernière partie)
- Etc.
La liste peut être longue, ce ne sont que quelques exemples ici (plus d’exemples dans la dernière partie). À vous d’identifier les petites variations qui permettent de créer “presque” le même composant à quelques détails près et voir du coup si un composant générique avec des options peut fonctionner, plutôt que plusieurs composants. En général, jeter un œil au modèle de contenu aide à identifier ces cas.
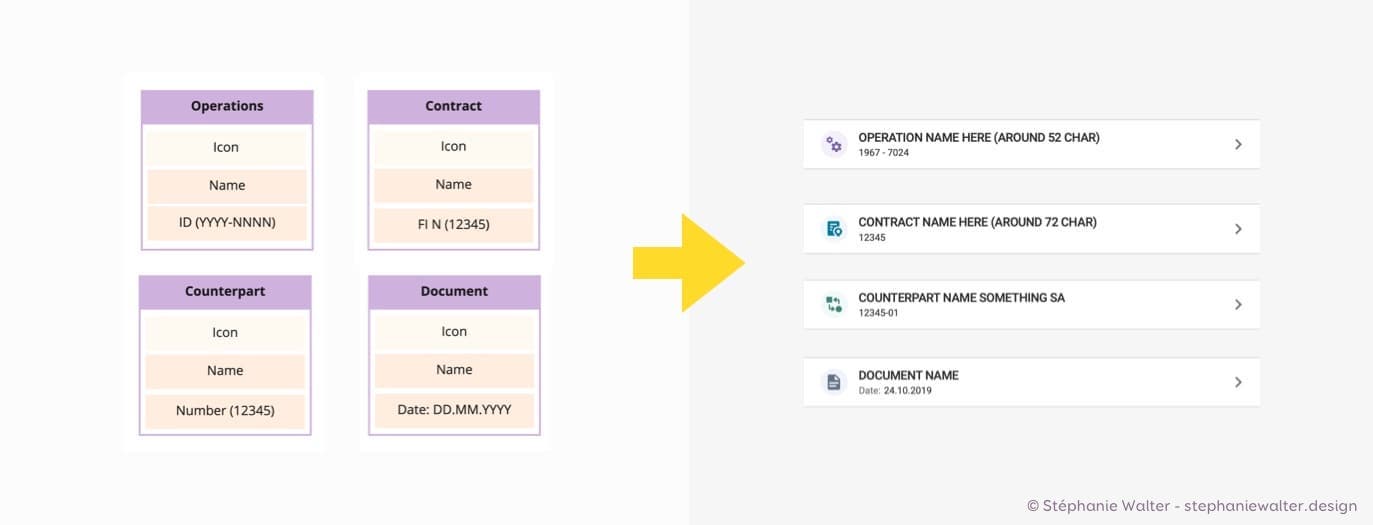
Des modèles pour les 4 types de contenus aux variantes de composants
Dans mon interface j’ai en fait 4 types de contenus liés qui vont avoir besoin d’un composant lien : opérations, contrats, contreparties et documents. Si on regarde le modèle de contenu de ces différents types, on se rend compte qu’il y a pas mal de similitudes.
Au final on pourrait utiliser le même composant, avec des variations.
4. Identifier les contextes de réutilisation
Au-delà des variations du composant liées à ses attributs et types de contenus, on peut aussi identifier que certains composants seront utilisés dans différents contextes. Par exemple, un composant de lien peut être utilisé dans une liste, mais peut-être aussi dans des résultats de recherche. Le même composant qui peut exister sur une appli web mais aussi sur App native mobile (donc optimisation au touch), sur un Google Nest Hub, Google TV, etc.
Sur mon site, il y a pleins d’endroits où on va utiliser ce composant de navigation vers un type d’entité:
- Sur la page d’accueil on a des listes de favoris
- À l’intérieur de certaines pages pour faire du maillage interne,
- Dans la recherche du site
C’est là où ça commence à devenir fun : la recherche sur mon site existe dans une taille moyenne sur la page d’accueil. Mais elle existe aussi dans une version “petite” à l’intérieur du site sur chaque page. Pour mon “entity link”, du coup j’ai donc désormais non seulement 4 “variations” mais également 2 tailles
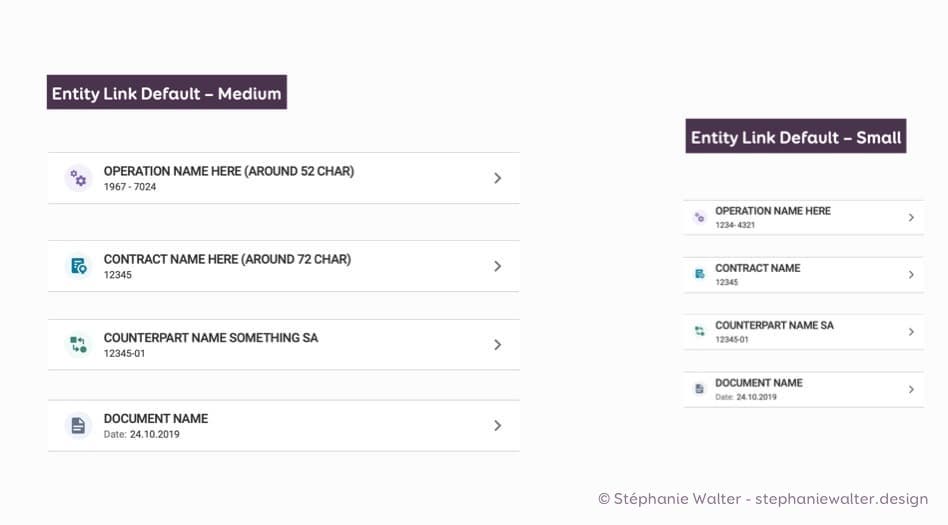
4 variations du composant et deux tailles (moyen et petit)
Variations et similarités : same player, play again !
Je décris tout cela dans la conférence et cet article de manière linéaire. Mais sur un projet ce n’est pas le cas. Souvent c’est un processus itératif où on réfléchit à plusieurs fois variations et similarités en même temps.
Mon composant “entity link” pourrait être réutilisé pour la page de résultats de recherche. Mais nous nous sommes rendu compte qu’en termes de priorité utilisateur, pour les résultats de recherche, il nous fallait afficher un peu plus d’informations que la version par défaut. C’est lié au fait que ce composant dans les résultats de recherche peut être filtré. Il nous faut donc un peu plus d’informations.
Nous avons étendu le modèle pour y inclure plus d’éléments qui étaient considérés comme priorité plus basse pour créer une variante.
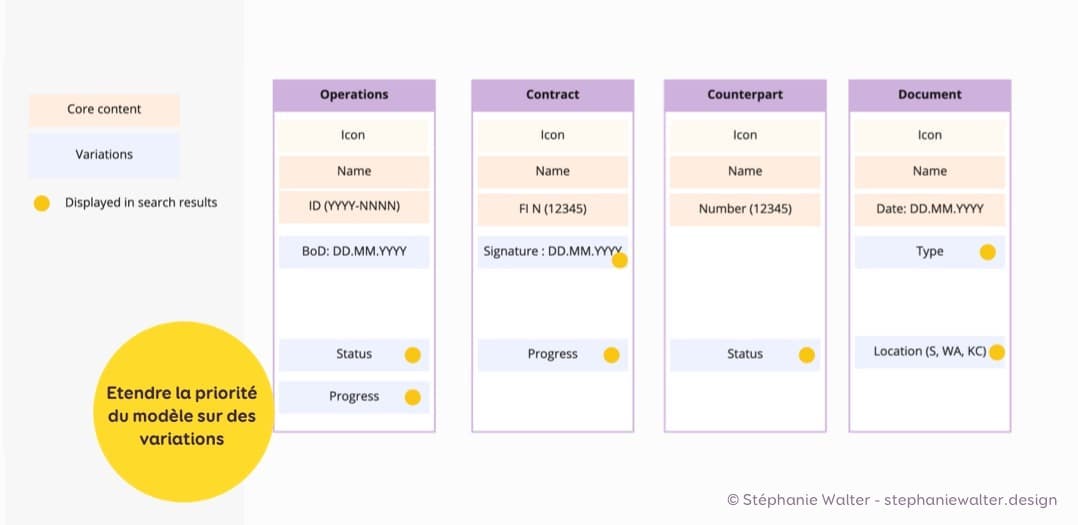
Étendre la priorité du modèle sur des variations en ajoutant des attributs de la liste
Dans notre design système, nous avons maintenant une variante qui affiche un peu plus d’informations que la version par défaut et qui est utilisée pour les résultats de recherche.
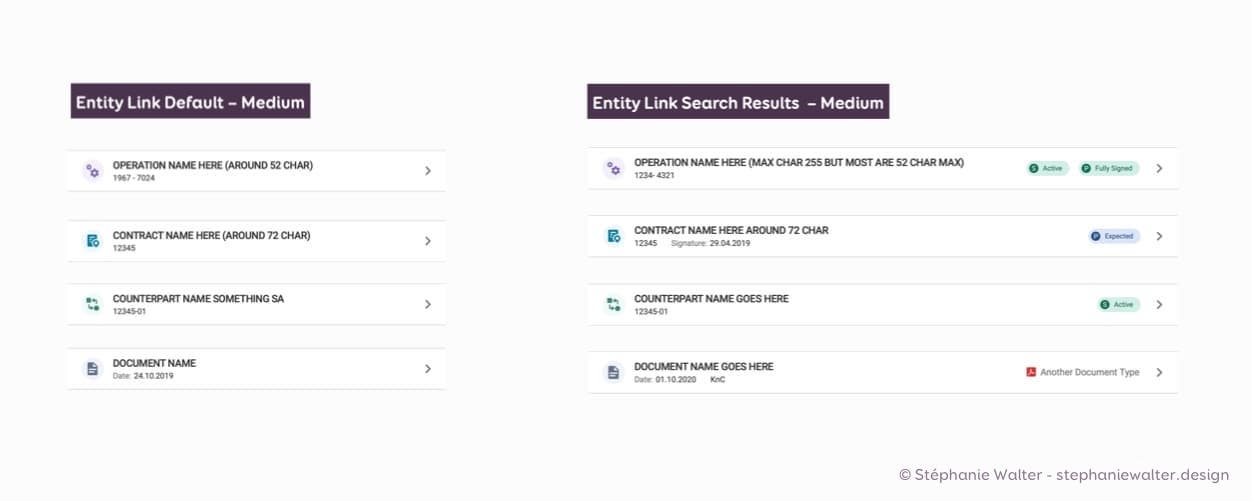
4 variations du composant de base, et 4 nouvelles variations pour les résultats de recherche
Bon je m’arrête là pour les exemples, mais sur le projet ce composant a encore quelques variations possibles.
Le principe reste le même :
- Modèle de contenu
- Tris et Priorité
- Comprendre les similitudes et ce qui est peut-être réutilisé
Du modèle de contenu aux zonings
Aujourd’hui avec le design système en place sur mon projet, je ne fais plus vraiment beaucoup de wireframes détaillés des composants. J’ai plutôt tendance à faire l’inventaire et prioriser. Ensuite, je reprends les attributs sur miro pour créer des zonings très basse fidélité de ce qui sera dans le composant. Puis je passe au design dans Sketch.
J’ai volontairement simplifié les exemples ci-dessus pour mettre l’accent sur le processus. L’étape “technique” entre est celle du “zoning”. Elle est assez minimaliste sur ce composant très simple et ressemble un peu à ça:
Du modèle de contenu, au zoning au composant final
On peut aussi utiliser ce modèle de contenu pour désigner des pages de détails en responsive par exemple. On arrive à un zoning précis qui permet ensuite souvent de passer assez rapidement à l’UI dans Sketch, surtout si on a une grosse partie des composants déjà dans le système :
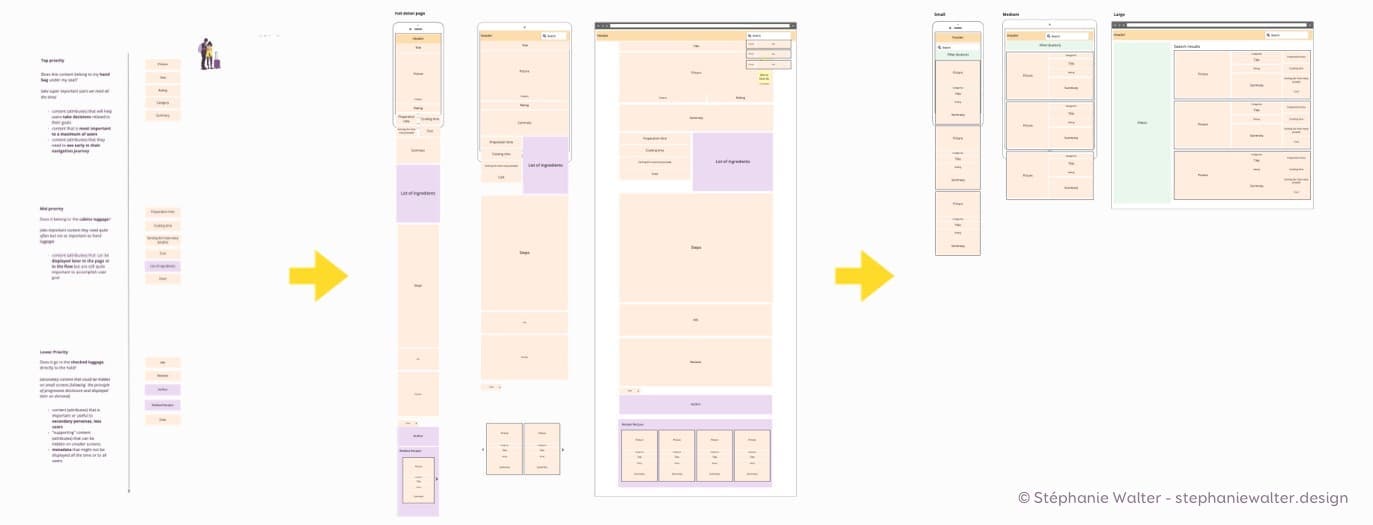
De la priorisation de contenu au zoning de 2 pages, une page de détails et une page de « liste »
D’ailleurs c’est une partie des méthodes que j’enseigne dans ma formation responsive à mes étudiantes et en workshop en petit comité. Si vous êtes intéressés par ce type d’enseignement pour votre conférence ou master class, envoyez-moi un e-mail.
Documentation et relation avec l’équipe de développement
Bien sûr, ce travail ne se fait pas en silo mais est en collaboration avec mon équipe de développement. Nous discutons pas mal avec l’équipe de développement pour ce type de composants, que ce soit sur le contenu ou la faisabilité technique.
Mais ce qui est clair aujourd’hui dans ma tête (et celle de mon équipe) ne le sera pas forcément dans 3 semaines ou un mois quand on va commencer vraiment le développement. Je documente donc beaucoup de choses pour ces composants :
- La version par défaut
- Les variations
- Et j’ajoute le modèle de contenu à ma documentation pour les aider à avoir une visualisation des similitudes et différences
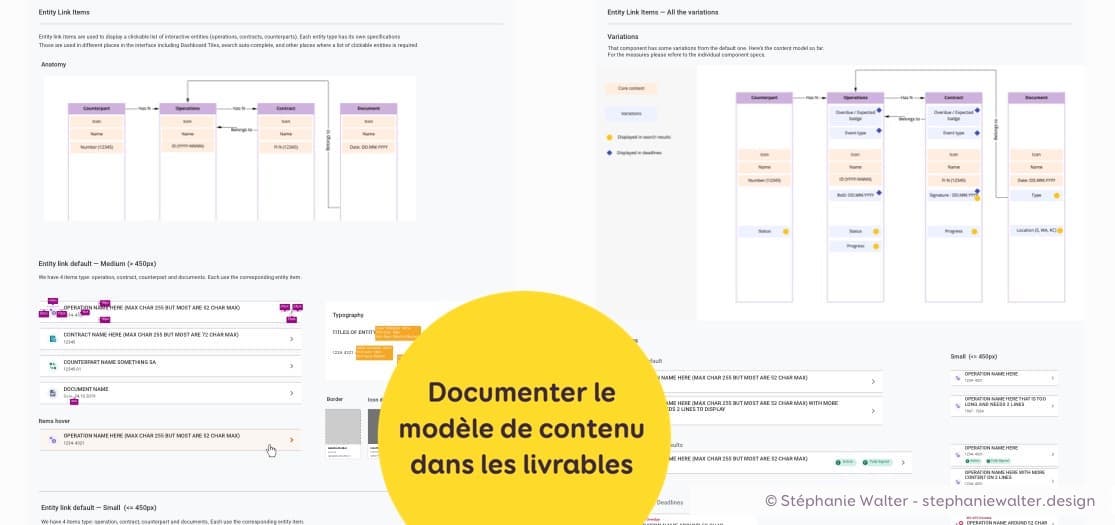
Après tout ce travail sur le modèle de contenu et les variations, le résultat final est un seul et unique composant, avec différentes options qui permet de gérer tous ces cas. Toute la complexité du composant a pu être résumée en 4 grosses zones que l’on remplit en fonction des options.
Gérer les variations d’un point de vue technique
Dans mon exemple, j’ai 2 versions : medium et small du composant. Pour la version small, on peut la faire en utilisant des techniques de responsive web design: utiliser des media queries pour gérer des variations de composant en fonction de la taille du viewport.
Le truc vraiment sympa et tout nouveau qui va permettre de pousser la modularité un cran plus loin avec les container queries.Au lieu d’adapter en fonction de la taille du viewport (media queries), on va pouvoir adapter le composant en fonction de la taille du container dans lequel on va le mettre. La bonne nouvelle c’est que cette spec arrive bientôt dans le navigateur!! Si vous n’avez pas la patience d’attendre, il est possible de les simuler avec beaucoup de JS (ce que nous faisons actuellement sur mon projet en attendant que les navigateurs implémentent Container queries.)
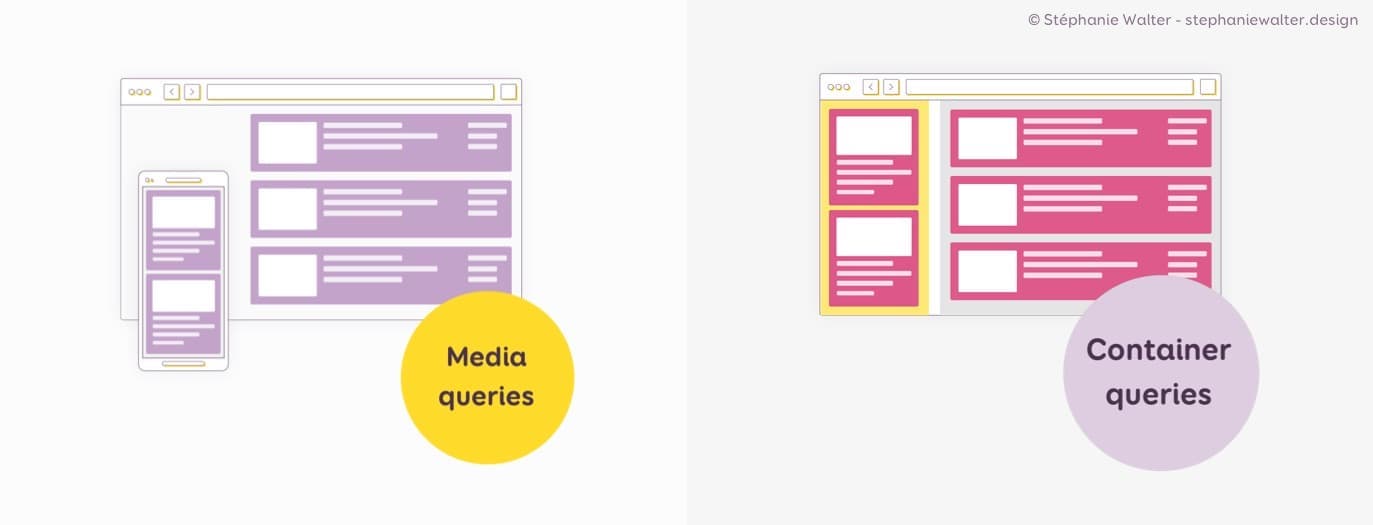
À gauche les media queries, permettent de modifier un composant en fonction de la taille du viewport. À droite, les container queries, permettent de modifier le composant en fonction de la taille de son parent / contenaire
Mais container queries n’est pas la seule chose qui permet de créer des composants capables de s’adapter tout seul en fonction de l’espace disponible. Pas mal de propriétés CSS plutôt bien supportées permettent d’aller très loin aujourd’hui dans la modularité: flexbox, grid, clamp(), etc.
D’ailleurs, en 2018 déjà, Jen Simmons dans sa conférence “Everything You Know About Web Design Just Changed” présentait déjà la notion de Intrinsic Web Design. Au lieu de changer de style en fonction de la taille du navigateur, elle propose de créer des composants dont la mise en page s’adapte automatiquement aux conditions idéales du navigateur. Elle y parle entre autres de grid layout.
Si je reprends mon exemple de site de restaurant, je pourrai avoir un composant “carte” qui est capable de s’adapter de manière horizontale ou verticale, à l’espace qui lui est dédié grâce à flexbox et clamp() (aucune media queries ici). Et si vous êtes curieuses de comment ça fonctionne techniquement, Geoffrey Crofte a fait un article détaillé :How to Make a Media Query-less Card Component
Ressources pour aller plus loin
- Container Queries Explainer & Proposal
- A Cornucopia of Container Queries rassemble en anglais pas mal d’articles et ressources sur les container queries
- CSS Container Queries For Designers et Say Hello To CSS Container Queries
- The new responsive: Web design in a component-driven world
- Container Queries are actually coming
- Flexible layouts without media queries
- Look Ma, No Media Queries! Responsive Layouts Using CSS Grid
- Create a responsive grid layout with no media queries, using CSS Grid
- Responsive CSS Layouts WITHOUT Media Queries
Designer dans les outils, Décider dans le navigateur !
Pour moi, si on veut arriver à créer des composants réutilisables, il faut sortir de l’obsession du “pixel perfect” et accepter la flexibilité des navigateurs.
Designer dans les outils,
Décider dans le navigateur !![]() Mon travail en tant que designer est de designer ces composants dans leurs “mise en page idéale”. Mes équipes de développement se chargent ensuite de fournir au navigateur les guidelines CSS pour se rapprocher autant que possible. Mais l’implémentation finale reste à la discrétion du navigateur.
Mon travail en tant que designer est de designer ces composants dans leurs “mise en page idéale”. Mes équipes de développement se chargent ensuite de fournir au navigateur les guidelines CSS pour se rapprocher autant que possible. Mais l’implémentation finale reste à la discrétion du navigateur.
C’est pour ça que je préfère voir le résultat final le plus tôt possible dans un navigateur, quitte à revenir sur mon design si besoin si des choses ne fonctionnent pas visuellement.
La dernière étape pour moi est donc cruciale : un retour ensemble en peer review avec les équipes de développement et de design pour discuter et voir le comportement réel du composant dans le navigateur. Et ajuster si besoin.
En temps normal c’est en face à face qu’on faisait ça. Mais avec la situation sanitaire, nous faisons ça via partage d’écran et Skype. Parfois j’adapte légèrement le design en fonction des retours des équipes de développement. Parfois on change directement certains paddings ou tailles dans le navigateur.
Au final c’est une collaboration où le composant Sketch sert surtout de référence. Mais ce qui compte, c’est son implémentation finale, d’un commun accord, dans le navigateur.
Variations et adaptations à différentes densités de contenus
Pour m’assurer que mes composants sont évolutifs, je fais non seulement attention à leur réutilisabilité, mais également au fait qu’ils vont pouvoir s’adapter à différentes densités de contenu si nécessaire.
Attributs de contenus manquants
Quand le contenu est généré par des utilisatrices et utilisateurs, certains attributs peuvent parfois ne pas être remplis, manquants ou ne pas exister pour certaines variantes.
Comment mon composant de “carte de recette de cuisine” va-t-il se comporter s’il n’y a par exemple pas d’image ?
- On affiche une image de remplacement (le logo par exemple)?
- On supprime l’image et le reste du contenu prend tout l’espace disponible ?
Quelle que soit la décision de design, mon équipe de développement va sans doute me poser la question. Cela leur permet d’anticiper et de construire un HTML/CSS flexible pour le composant.
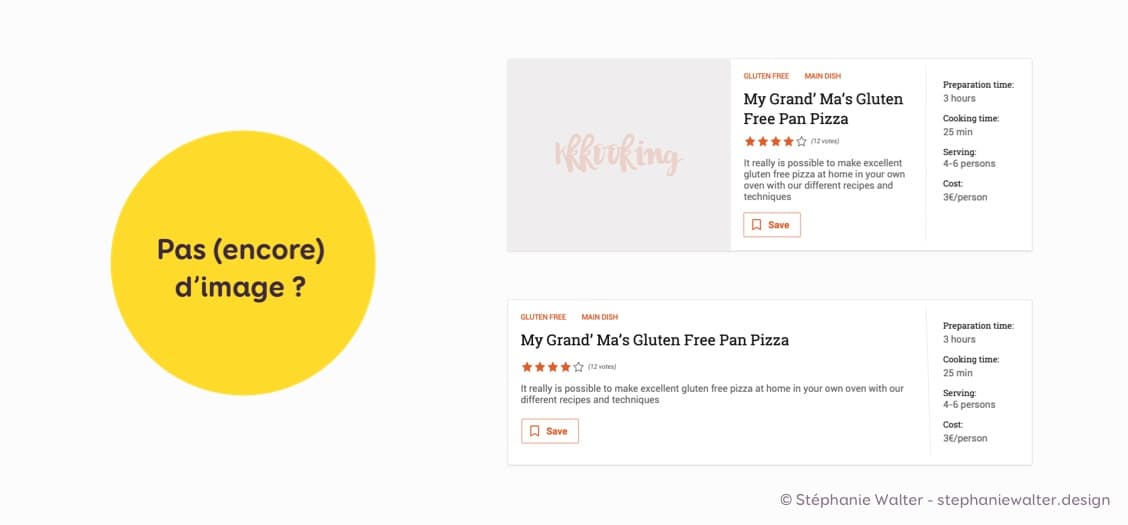 Sur ce même composant, que se passe-t-il s’il n’y a pas (encore) de valeur pour les votes ?
Sur ce même composant, que se passe-t-il s’il n’y a pas (encore) de valeur pour les votes ?
Une note de 0 parce que personne n’a émis d’avis sur la recette n’est PAS la même chose qu’une note de 0 parce que tout le monde déteste la recette ! Que fait-on ?
- Afficher la valeur “0 votes” pourrait fonctionner visuellement. Mais cela donne une fausse impression que la recette n’est pas bonne
- On pourrait changer ce composant pour afficher « pas encore de votes » à la place
- On pourrait aussi ne pas du tout afficher cette partie du contenu, mais là encore, ça pourrait porter à confusion.

La réponse dépend de pleins de critères. Mais c’est le genre de chose que l’on va devoir anticiper pour créer des composants réutilisables qui peuvent s’adapter à tout type de contenus.
Plus de contenu qu’initialement prévu
Je viens de vous donner des exemples de “pas” ou “pas assez” de contenus. Une autre question que j’ai tendance à me poser est : que se passe-t-il s’il y a plus, ou trop de contenu?
Par exemple, si mon composant de “Liste de favoris” à 40 éléments, on fait quoi ?
- Pagination et on affiche les N premiers ?
- On fixe la hauteur et on scroll ?
- On ne fixe rien du tout et la carte s’étend en hauteur ?
Là encore, ça dépend de pleins de choses, mais il faut le prévoir.
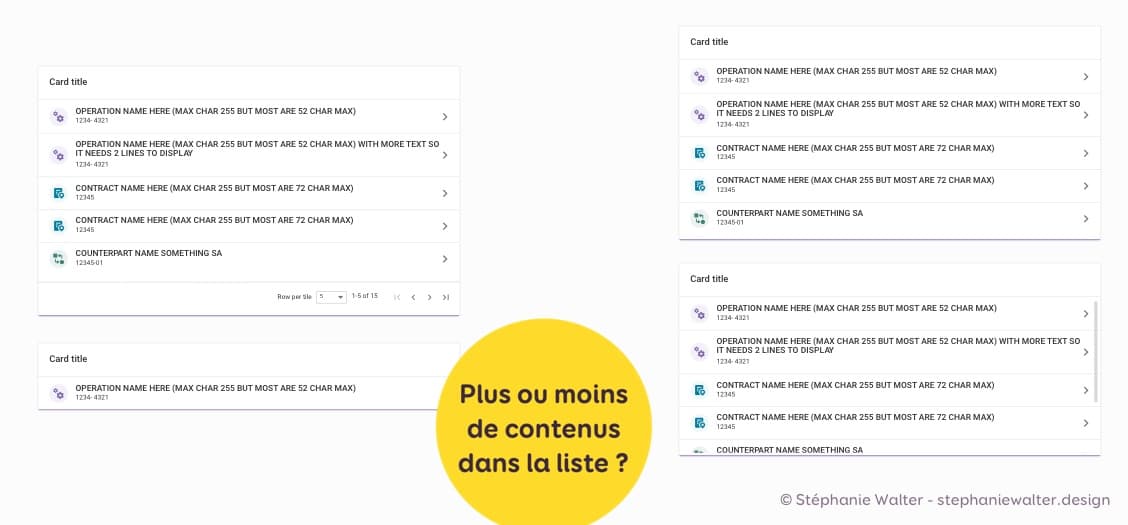
Des attributs de contenu plus longs que prévu
Parfois, il faut également gérer la densité du contenu à l’intérieur du composant.
Si je reprends mon exemple de recette de cuisine, que doit-on faire si le titre a besoin de 2 lignes. Il prend 2 lignes. Okay, jusque-là ça parait évident. Mais comment le reste du composant va-t-il se comporter ?
- Que faisons-nous du recadrage de l’image ?
- Qu’advient-il des métadonnées de droite ? On les aligne en haut ? Au centre ?
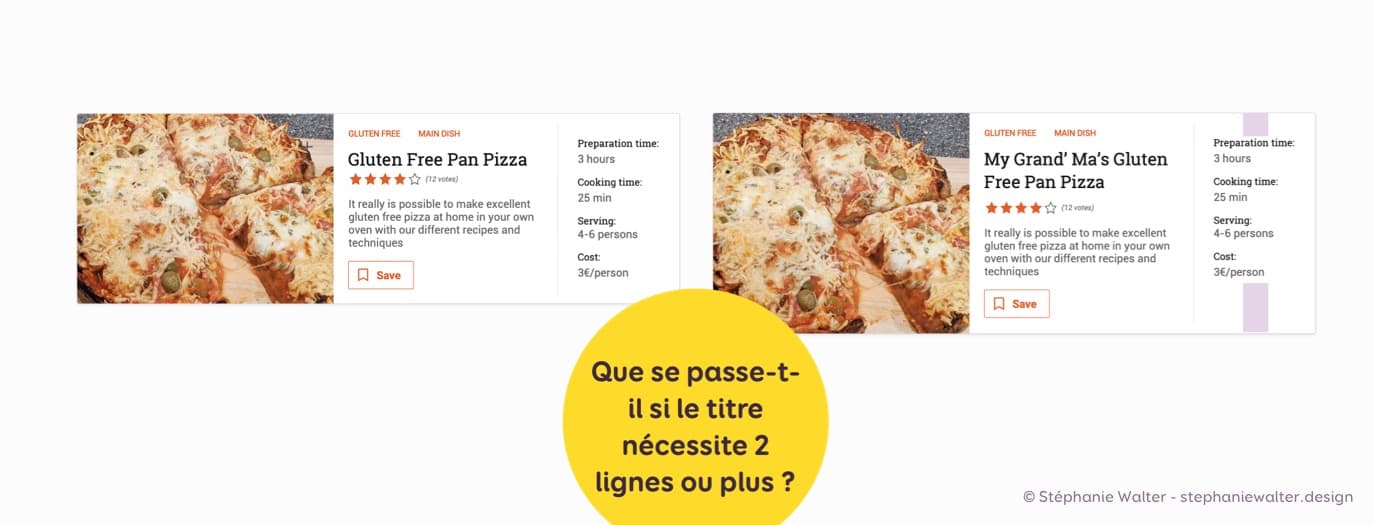
Des exemples comme ça, j’en ai pleins dans mon design système
- Comment s’alignent les cellules de tableau si le contenu prend 2 lignes ? En haut ? Centré ?
- Il se passe quoi quand la description fait plus de 300 caractères, on a quand même 10% des entrées dans la base de données pour lesquelles c’est le cas ! (on a mis un “lire la suite” pour ces 10%)
- etc.
Comment anticiper le contenu flexible
Voici quelques conseils pour vous aider à anticiper ces cas. On en revient très souvent à la même chose : la discussion entre équipes de design et de développement.
- Évitez le “lorem ipsum” et autres faux contenus. Si vous ne pouvez pas l’éviter, assurez-vous que la structure soit aussi proche que possible du vrai contenu.
- Discutez avec votre équipement de développement pour savoir quelles sont les limites dans la base de données. Demandez la longueur minimale, maximale et surtout la taille moyenne du contenu.
- Soyez pragmatiques : si la taille moyenne est de 300 caractères mais que 10% des cas ont 1000 caractères, désignez pour les 300 caractères et prévoyez une adaptation pour les 1000 (lien lire la suite, etc.)
- Pour les équipes de dev : si quelque chose manque, demandez à l’équipe de design comment le composant doit se comporter.
- Pour les traductions : essayez de savoir dès le départ si vous avez besoin d’autres langues, lesquelles, et le ratio de traduction
Finalement, ce qui est à retenir : Je n’ai pas besoin de les « designer » tous, mais surtout de « décider » de ce qui va se passer et de le communiquer à l’équipe de développement.
Chargement, population de données, erreurs et l’absence de données
Une grosse partie de notre interface sont des cartes dans lesquelles sont chargés différents types de contenus. J’ai donc en plus, plusieurs états de “population de données” : chargement, pas de données (état vide), erreur. Ces états sont “génériques” et les mêmes quel que soit le contenu. Je n’ai pas besoin, pour chaque nouvelle carte, de “redesigner” ces états.
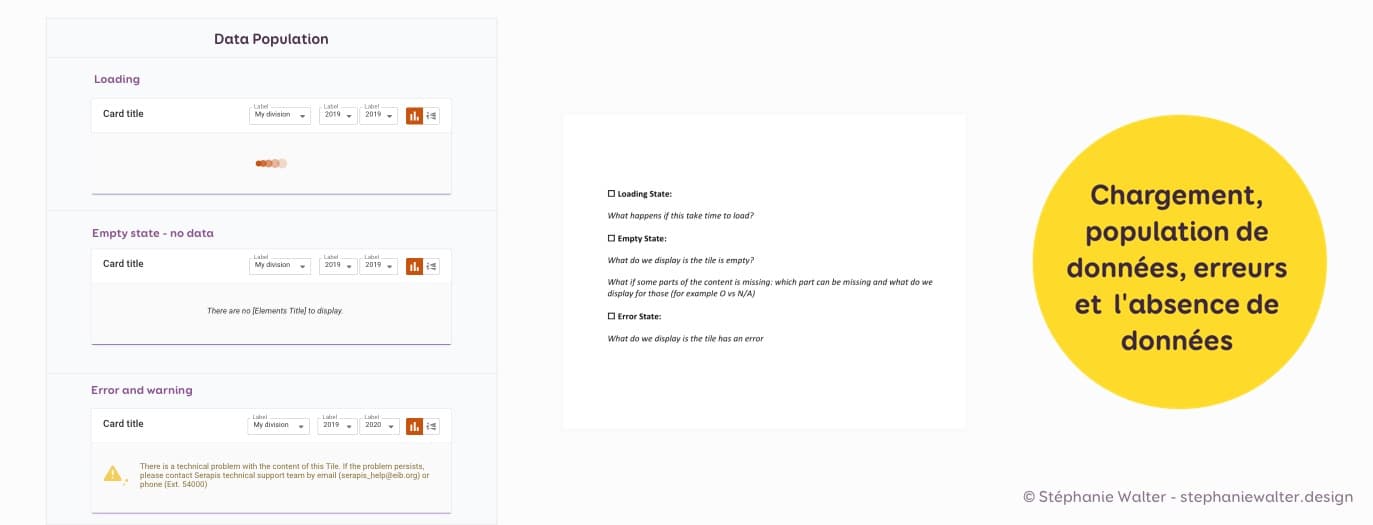 J’essaie généralement de documenter la façon dont les composants sont censés fonctionner à un niveau générique dans notre “styleguide” (sur Sketch). Les messages d’erreur et cas vide quant à eux sont documentés au cas par cas dans le ticket Jira. Nous avons également maintenant une checklist pour ne pas oublier des états quand on rédige les tickets techniques Jira.
J’essaie généralement de documenter la façon dont les composants sont censés fonctionner à un niveau générique dans notre “styleguide” (sur Sketch). Les messages d’erreur et cas vide quant à eux sont documentés au cas par cas dans le ticket Jira. Nous avons également maintenant une checklist pour ne pas oublier des états quand on rédige les tickets techniques Jira.
Variations et adaptations liées à l’interactivité et au contexte d’usage
Pour le moment j’ai surtout parlé de composants “statiques” avec peu d’interactions. Mais bon nombre de composants d’un système sont des composants de navigation, de recherche, de formulaire avec bien plus d’interactions que juste un clic sur une carte.
Ces composants vont souvent avoir plusieurs états qu’il va falloir prévoir en fonction de différents contextes
Pensez à différents états interactifs
La 1e chose à laquelle on pense, quand on dit “interaction”’ c’est les interactions avec les éléments de formulaire. Un “simple” composant de champ texte n’est au final jamais aussi simple, puisqu’on va devoir prévoir beaucoup d’états différents. Par exemple :
- Par défaut, rempli et non rempli
- Au survol, rempli et non rempli
- Au focus clavier, rempli et non rempli
- Avec / sans placeholder.
Et puis on va avoir les états de validation, par exemple
- Information
- Erreur
- Warning
- Succes
Tout cela, multiplié par le nombre de composants de formulaires, ça commence à faire pas mal de choses à ne pas oublier.

Et plus le composant sera compliqué, plus on aura d’interactions à prévoir.
Pensez à la navigation clavier, touch et autres interactions
Et n’oubliez pas la navigation au clavier, très utile pour des questions d’accessibilité mais également souvent pour des utilisatrices avancées.
Voici un exemple, sur un composant de menu déroulant :
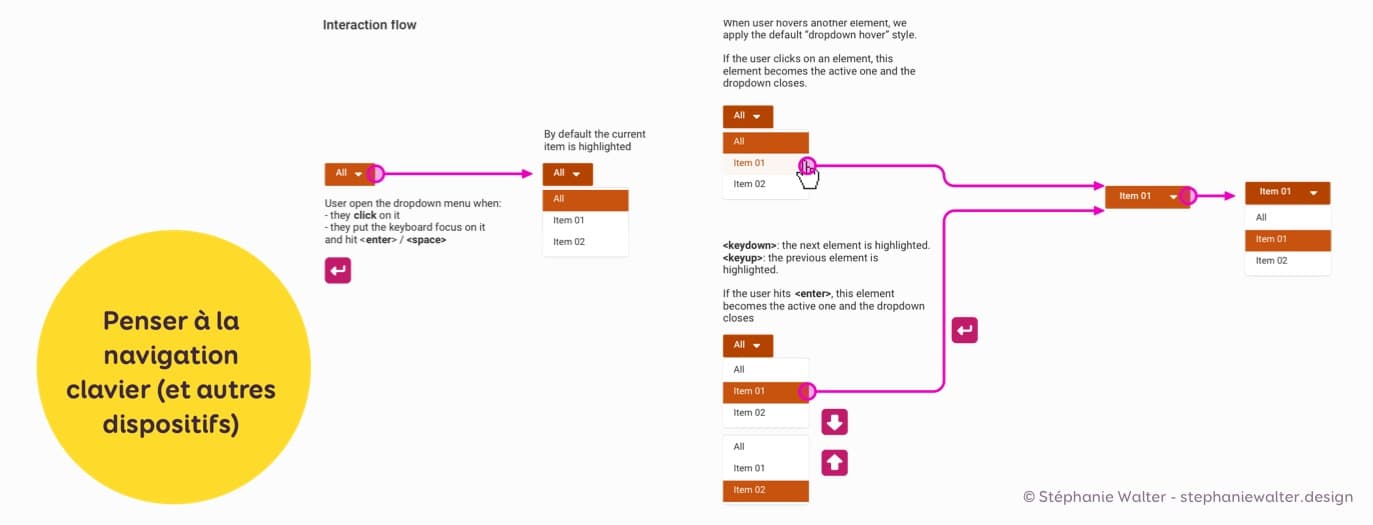 Souvent, c’est encore une fois une collaboration avec les équipes de développement, car l’implémentation n’est pas toujours facile.
Souvent, c’est encore une fois une collaboration avec les équipes de développement, car l’implémentation n’est pas toujours facile.
Il en est de même pour les interactions au toucher. Parfois elles peuvent être différentes d’une interaction classique. Par exemple : le carrousel d’images doit-il fonctionner au swipe ? Là encore, pas mal de choses à discuter avec les équipes de dev.
Les “livrables” UX pour communiquer les interactions aux équipes de développement
Une grosse partie de nos outils de conception nous obligent encore à concevoir des images statiques de « ce à quoi le produit ressemblera”. Cela rend parfois la communication d’états très interactifs un peu compliquée. Ça avance un peu (avec certaines mises à jour de Figma), on va vers plus en plus d’interactivité.
Certains de nos livrables “UX” peuvent également servir aux équipes de développement pour communiquer les interactions.
C’est le cas par exemple de tout ce qui est task flow et user flows (qu’on transforme en screenflow quand on y ajoute les écrans). Ils permettent aux équipes de dev et à mon testeur de mieux comprendre comment vont se comporter les composants, vont s’enchainer les vues et écrans, etc.
 Je suis également une grande fan de la philosophie« show don’t tell » (montrer plutôt que raconter). Je crée souvent des prototypes interactifs pour les tests utilisateur. J’attache ces prototypes aux stories dans Jira car ce sont des démos précieuses de “comment l’App est censée fonctionner”, “comment les écrans s’enchaînent », etc.
Je suis également une grande fan de la philosophie« show don’t tell » (montrer plutôt que raconter). Je crée souvent des prototypes interactifs pour les tests utilisateur. J’attache ces prototypes aux stories dans Jira car ce sont des démos précieuses de “comment l’App est censée fonctionner”, “comment les écrans s’enchaînent », etc.
Sur du mobile par exemple, cela m’aide à communiquer les animations entre les écrans. Ça me permet aussi de simuler tout ce qui est navigation sticky, etc.
Je préfère Axure parce qu’il est puissant en termes d’interactions (puisque ça génère du HTML/CSS/JS). Mais Figma commence à proposer des options intéressantes aussi. Pas mal d’outils existent pour créer des animations et interactions, à vous d’explorer ce qui fonctionne pour VOS besoins. Un outil reste un outil.
Variations en fonction de l’état du système
Je vous ai parlé de l’identification des variations plus haut. Je vous ai parlé des états de certains composants (formulaires) en fonction des interactions avec les utilisatrices.
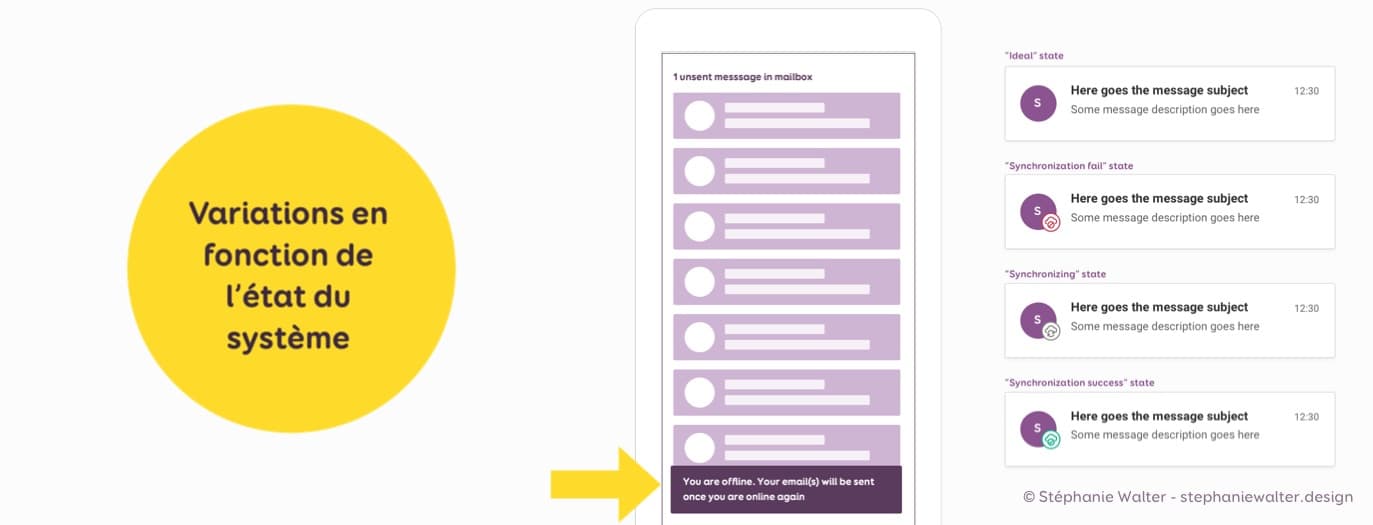
Certains composants peuvent également avoir des variations en fonction de l’état du système.
Par exemple, si on propose de la synchronisation “hors ligne” en tâche de fond (sur une App native mais ça arrive sur le web), d’un coup il va falloir penser à de nouveaux états pour le composant :
- État idéal (tout va bien c’est synchronisé)
- État “perte de synchronisation”
- État “synchronisation en cours”
- État de “succès de synchronisation”
- Combien de temps reste-il avant de retourner à l’état idéal ?

- On va également sans doute vouloir ajouter des notifications au système pour informer la personne au moins de l’échec (ou succès) de la synchronisation.
Variations en fonction de l’étape du parcours
On pourrait aussi avoirdes variations en fonction de l’étape du parcours. On peut par exemple penser aux états “vides” de certains composants d’application ou de Dashboard : à quoi ressemble le composant quand la personne est au début de son parcours et n’a pas (encore) créé (ou reçu) de contenus ? Je vous avait également donné l’exemple plus haut d’un composant qui peut-être, en fonction de l’étape du parcours, en lecture seule ou en édition. Ça aussi, il va falloir le prévoir.
Certains parcours suivent un chemin linéaire de type “étape par étape”. Voici, par exemple, une application pour déposer sa voiture au garage en dehors des horaires d’ouvertures (j’ai changé les couleurs de la charte ici pour des raisons de confidentialité du client). Les composants sont génériques mais on va devoir prévoir des adaptations en fonction de l’étape dans le parcours.
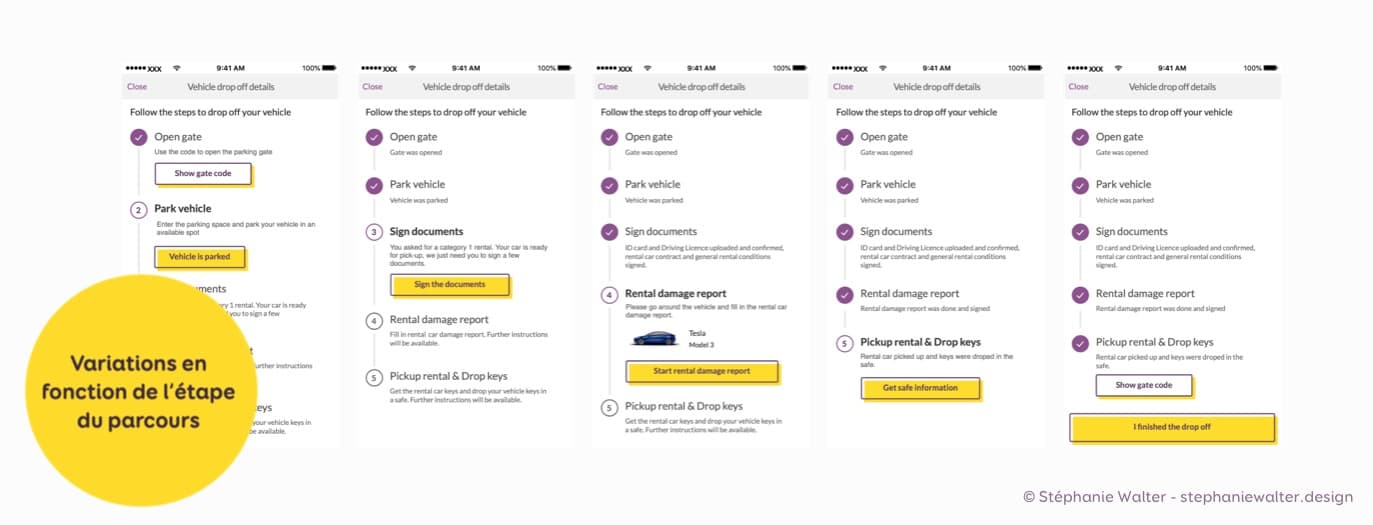
Pareil pour les applications de e-commerce (Amazon) dans la partie “suivi du colis”, en fonction de l’étape dans le processus, les composants peuvent changer de forme.
Un outil très utile pour comprendre les différentes étapes d’un parcours utilisateur est la création d’un user journey map à partir des données récoltées durant la recherche utilisateur. Je vous renvoie à mon article et template “Introduction aux « User Journey Maps » + modèles PDF à télécharger”
S’adapter aux préférences utilisateur
Dès qu’on commence à creuser un peu dans les capacités techniques de nos appareils et navigateurs, on se rend compte que l’on peut faire pleins de micro-adaptations pour suivre les préférences utilisateur.
Nos appareils proposent presque tous un mode jour / nuit (dark/light mode). On pourrait donc imaginer adapter ses composants également en fonction de ces préférences.
Par contre, attention, créer un thème “sombre” n’est pas simple et prend beaucoup de temps. On ne peut pas juste inverser les couleurs. Je vous renvoie à “Dark Isn’t Just a Mode” pour plus de détails sur le sujet.
Si on combine cela à certaines APIs qui permettent de récupérer par exemple la position de l’utilisatrice (GPS) et la luminosité dans l’habitacle d’une voiture, on peut créer des applications de GPS dont les composants changent automatiquement en mode sombre si on détecte que la personne est dans un tunnel. Avi dans son article Creating An Adaptive System To Enhance UX imaginait déjà en 2012 comment on pourrait créer des systèmes plus “adaptatifs”.
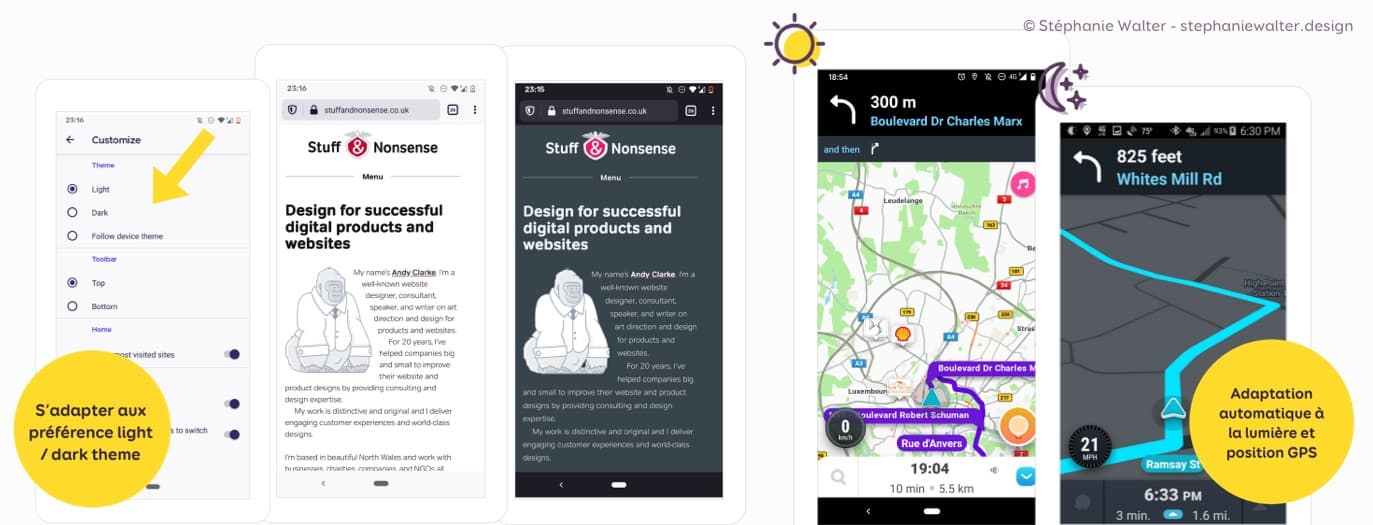
Attention, dans tous les cas, si vous adaptez vos interfaces et composants automatiquement en fonction de certains critères, laissez les gens désactiver les fonctions d’adaptation automatiques au besoin. Cela permet d’éviter de créer des interfaces qui font des choix qui ne conviennent parfois pas. Quand je fais du vélo, Google Maps passe son temps à essayer de me remettre sur la route que l’App préfère (car la moins “longue” en termes de temps). Le souci est que cette route est dangereuse. Merci Gmaps, mais non merci. Je sais mieux quelle route je veux prendre. J’ai juste besoin du GPS dans les petites ruelles à cause des sens uniques. Pourtant sur mon dernier trajet, malgré le fait que j’ai re-selectionné à la main la route souhaitée, Gmaps m’a remis sur sa préférée 3 fois de suite. C’est très exaspérant. Donc faites attention avec tout ce qui est adaptatif.
Enfin, notez qu’au-delà du dark mode, il existe plusieurs autres préférences utilisateur auxquelles vous pouvez adapter vos composants. Je vous explique notamment comment adapter vos animations aux préférences “prefers-reduced-motion” dans mon article sur les animations CSS et l’experience utilisateur (en anglais). Pour plus d’idées d’adaptations, je vous renvoie à “Beyond screen sizes: responsive design in 2020”.
Faites votre recherche et tests utilisateurs !
Vous êtes arrivés presque à la fin de l’article. Merci d’avoir lu jusque-là. Mais vous devez sans doute vous demander, quel est le secret au final, pour designer du coup tous ces composants de la meilleure façon, avec le bon contenu, pour qu’ils s’adaptent correctement aux besoins ? Eh bien, il n’y a pas de recette magique, on en revient toujours à la même chose : faites votre recherche utilisateur. Faites des tests. Itérez. Trompez-vous, recommencez.
C’est ce qu’on a mis en place sur notre design système. On ne va pas forcément tester les composants un par un, mais ils seront testés soit durant des tests utilisateurs, soit durant des sessions en beta, en les utilisant en contexte dans les pages que l’on va construire. Et on les travaille au besoin en fonction des retours.
La partie recherche et tests est en dehors du cadre de cet article, mais abonnez-vous au blog en anglais car je vais essayer de détailler un peu plus cette partie dans les mois à venir dans une série d’articles dédiés à la recherche utilisateur sur des produits internes.
En résumé, le TL;DNR
En résumé, ce qu’il faut retenir si on veut créer des composants qui sont évolutifs et réutilisables :
- Faire sa recherche utilisateur en amont
- Partir du modèle de contenus et travailler son architecture d’information
- Identifier les variantes et similarités
- Anticiper la flexibilité du contenus et états de chargement
- Anticiper différentes interactions avec les composants, qu’elles soient humaines ou machines
- Tester les composants, itérer, adapter
- Il s’agit d’un processus de collaboration avec votre équipe de développement !
Et mercià Audrey Hacq pour les retours sur la conférenc et à Fabien Rassinier pour les feedback sur l’article :)
La vidéo de la conférence
La dernière version de cette conférence a été au Design Summit 2021. Vous pouvez consulter la vidéo ci-dessous (l’article est un peu plus détaillé que la vidéo).